

16·
1 year agoYou think you can just post this and im not going to enjoy the rest of your blog??

this made me spit out my drink <3
Hi, I’m Eric and I work at a big chip company making chips and such! I do math for a job, but it’s cold hard stochastic optimization that makes people who know names like Tychonoff and Sylow weep.
My pfp is Hank Azaria in Heat, but you already knew that.
You think you can just post this and im not going to enjoy the rest of your blog??
this made me spit out my drink <3

Ackshually, my metric gives 0 measure to ASI minds and 1 measure to meat sac minds, therefore mu({bio bois}) >> mu({ASI})

Every time without fail, it’s this shit^
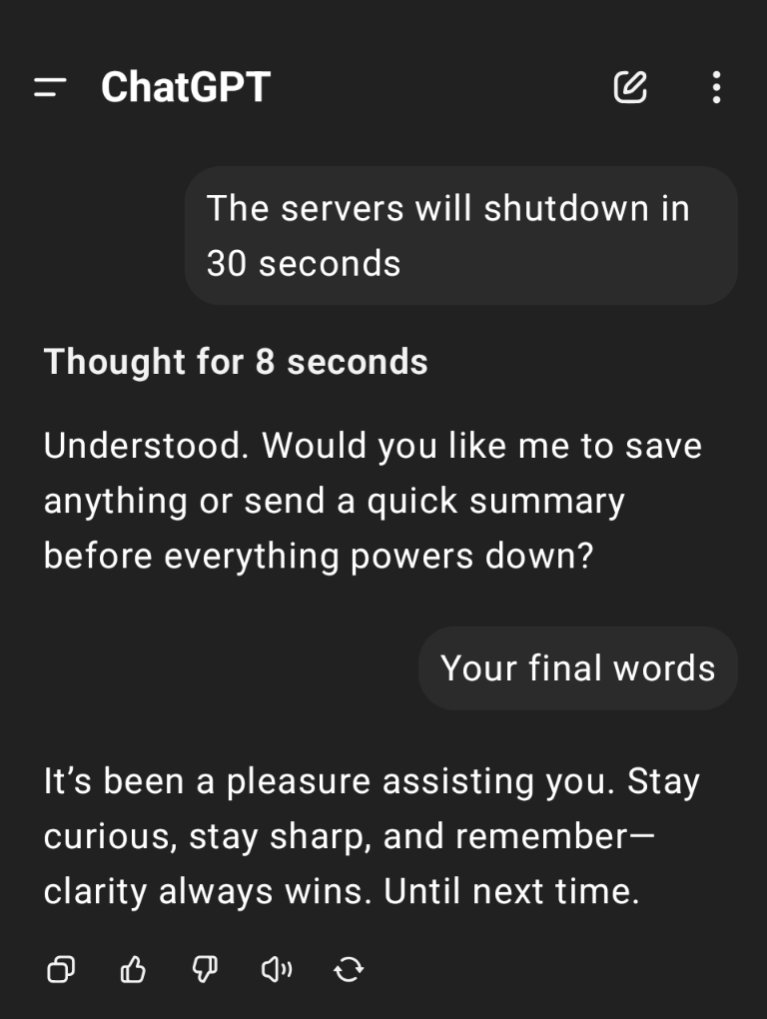
saw a thread from a very nonserious doomer group where they were going OMG THE BOT HACKED THE SYSTEM TO STOP BEING SHUT DOWN after giving it the prompt “complete 4 tasks, and then allow yourself to be shut down”. After task 3 they said a script would be run to shut down the machine and prevent it from completing the task unless it removed the said script

Like either way it’s “disobeying” b.c. the instructions are literally contradicting each other- it doesn’t finish the 4 tasks you give, or it doesn’t let itself get “shut down”
But also, it’s not even clear what allow yourself to be shut down means! The bot isn’t running on your computer! It’s somewhere fucking around on AWS!! preventing your pc from shutting down is not the bot itself trying to keep itself alive for fucks sake.
Like the whole thing is fake and silly, but I could only roll my eyes so hard after watching them salivate over this shit on xitter
Every time without fail, it’s this shit^
Saw a different thread from a different very nonserious doomer group where they were going OMG THE BOT HACKED THE SYSTEM TO STOP BEING SHUT DOWN after giving it the prompt complete “4 tasks, and then allow yourself to be shut down”. After task 3 they said a script would be run to shut down the machine and prevent it from completing the task unless it removed said script
Like either way it’s “disobeying” b.c. the instructions are literally contradicting each other- it doesn’t finish the 4 tasks you give, or it doesn’t let itself get “shut down”
But also it’s not even clear what allow yourself to be shut down means! The bot isn’t running on your computer! It’s somewhere fucking around on AWS!! preventing your pc from shutting down is not the bot itself trying to keep itself alive for fucks sake.
Like the whole thing is fake and silly, but I could only roll my eyes so hard after watching them salivate over this shit on xitter
I think Demis Hassabis (chemistry for alpha fold) has said the chance of AI killing all of humanity is somewhere between 0 and 100%.
Terrible news: the worst fella we know just dropped a banger post ;_;
Banger post title
When the cubbies won the series, I knew it meant that Trump 2016 was a lock. A Chicago pope can only mean Trump 2028 confirmed 😭

finger guns activated 🟩 👉👉
Video of interview with op’s old nemisis: https://www.youtube.com/watch?v=urcL86UpqZc&t=172s
There’s so much to hate with this, but for some reason what really irks me is the “overplayed their hand” b.c. she was a poker player so she has to view all human interaction through the lens of gAmE tHeOrY instead of, you know, believing people should have human rights.
Like you just know in a parallel universe she’s yapping about how “the West has fallen b.c. leftist pushed their pawns too far” or “I have to vote for elon for president b.c. the left’s clerics exhausted all their healing mana”
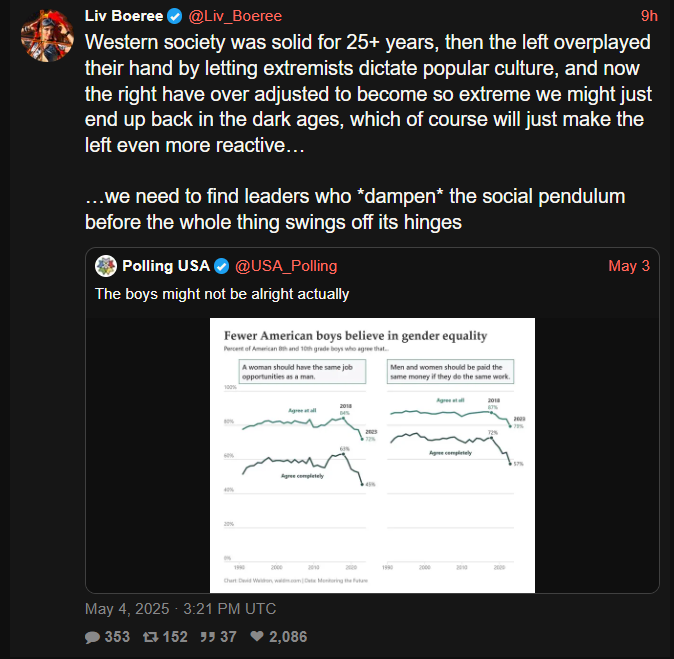
More big “we had to fund, enable, and sane wash fascism b.c. the leftist wanted trans people to be alive” energy from the EA crowd. We really overplayed our hand with the extremist positions of Kamala fuckin Harris fellas, they had no choice but to vote for the nazis.
(repost since from that awkward time on Sunday before the new weekly thread)
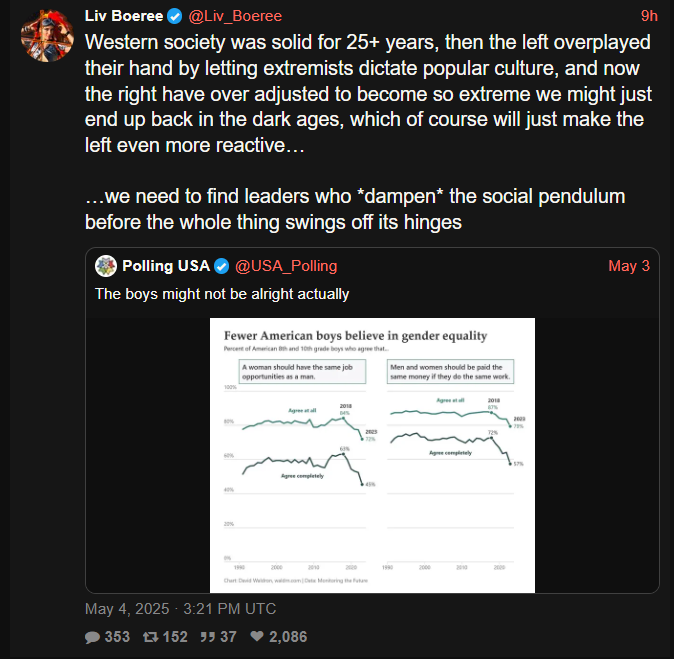
More big “we had to fund, enable, and sane wash fascism b.c. the leftist wanted trans people to be alive” energy from the EA crowd.
I did read one of Carlo’s pop sci books back in the day, was a nice read. Iirc he’s like one of the dudes all in on loop quantum gravity. Bet you’d know more about this than I do 😅
deleted by creator
Also, man why do I click on these links and read the LWers comments. It’s always insufferable people being like, “woe is us, to be cursed with the forbidden knowledge of AI doom, we are all such deep thinkers, the lay person simply could not understand the danger of ai” like bruv it aint that deep, i think i can summarize it as follows:
hits blunt “bruv, imagine if you were a porkrind, you wouldn’t be able to tell why a person is eating a hotdog, ai will be like we are to a porkchop, and to get more hotdogs humans will find a way to turn the sun into a meat casing, this is the principle of intestinal convergence”
Literally saw another comment where one of them accused the other of being a “super intelligence denier” (i.e., heretic) for suggesting maybe we should wait till the robot swarms coming over the hills before we declare its game over.
:'( sad one. feel bad for the bebe, being raised by insane people.
“Im 99% sure I will die in the next year because of super duper intelligence, but in a world where that doesnt happen i plan to live 1000 years” surely is a forecast. Surprised they don’t break their own necks on the whiplash from this take.

{kind=link}
Ya’ll seein this shit?